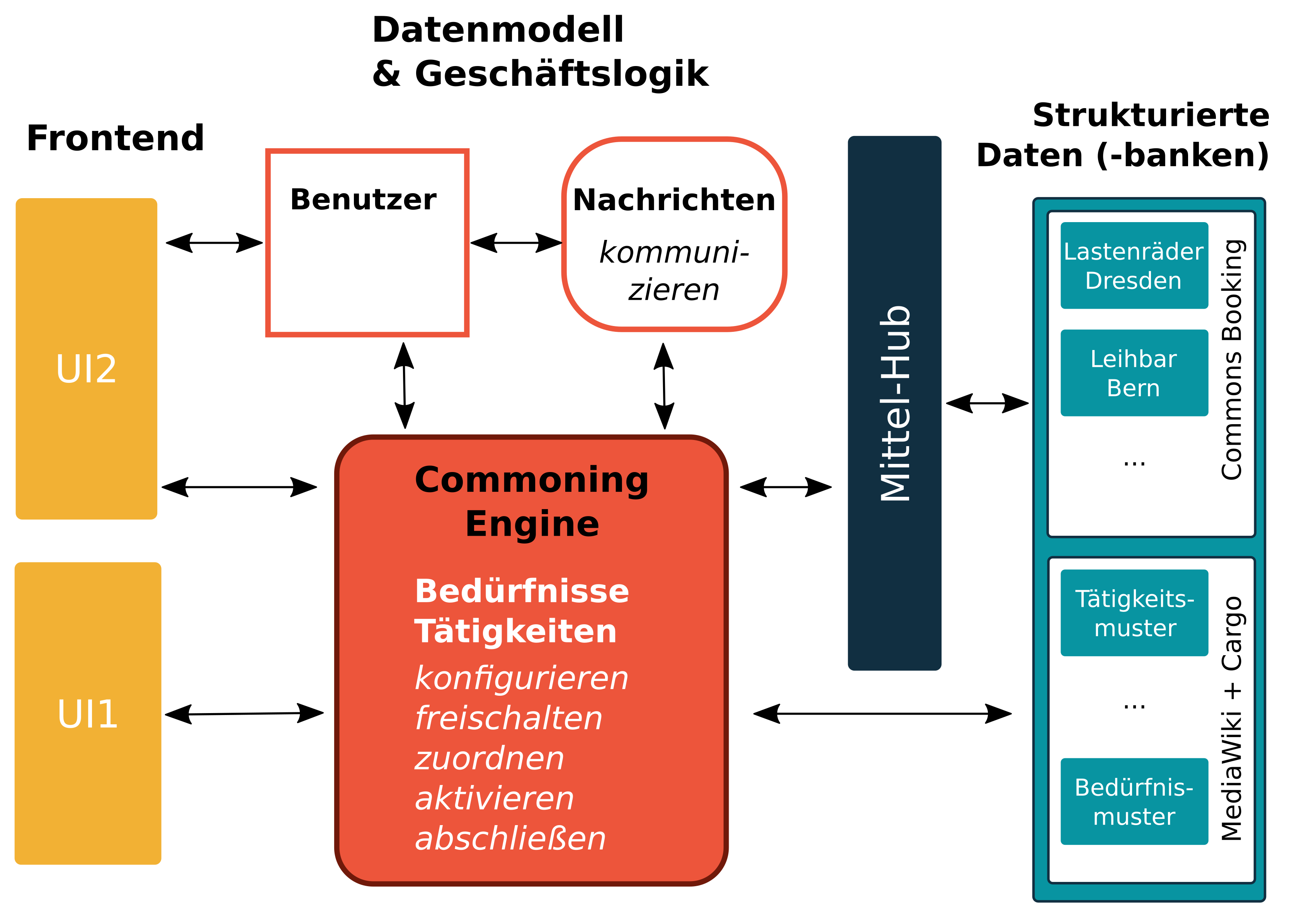
Ausgehend von der folgenden Beschreibung haben wir weiter unten eine Grafik entwickelt. Im Beitrag zur Commoning Engine wird diese erstmalig beschrieben und die Struktur damit neu definiert. Dieser Beitrag dient dennoch als wichtige Referenz für einige Details.
Die Software lässt sich in Bausteine zerlegen. Idealerweise definieren die Komponenten klare Schnittstellen. Unter Berücksichtigung dieser Schnittstellen können sie dann weitestgehend unabhängig voneinander entwickelt werden, es ist auch kein Problem, wenn sie sich technologisch unterscheiden.
Dieses Dokument ist Work in Progress, es ist also nicht fertig. Bei der Diskussion verfasst bitte separate Posts zu den einzelnen Komponenten, dann lässt sich die Diskussion leichter moderieren.
Komponente (1): Wissensdatenbank
- Kapselt den Zugriff auf eine oder mehrere Wissensdatenbanken (mit oder ohne Cache).
- Prominentes Beispiel ist Wikidata, diese sollte in jedem Fall angebunden werden.
- Weitere Datenbanken decken typischerweise domänenspezifische Teilbereiche ab (beispielsweise MusicBrainz)
- Komponente
conceptsdes Mini-Prototypen - Schnittstelle (1a):
- Anfrage von Begriffen und den zugehörigen Beziehungen (Taxonomie)
- Schnittstelle (1b):
- Aktualisierung der Wissensdatenbank
Komponente (2): Mitteldatenbank
- Kapselt den Zugriff auf alle verwendbaren bestehenden Mitteldatenbanken (beispielsweise für Lastenfahrräder).
- Legt zusätzliche Mittel in einer eigenen Datenbank ab.
- Implementiert APIs wie die Commons API, sowohl zum Zugriff auf externe Datenbanken als auch um eigene Mittel nach außen anzubieten.
- Ordnet jedem Mittel ein Mittelmuster zu (unter Verwendung der Schnittstelle (4a)).
- Ermöglicht eine „Reservierung“ von Mitteln.
- Komponente
meansdes Mini-Prototypen - Schnittstelle (2a):
- Anfrage von vorhandenen Mitteln (auf Grundlage eines Mittelmusters)
- Reservierung von Mitteln
- Ob die Commons API hierfür verwendet werden kann, muss geprüft werden.
- Im Prinzip handelt es sich um einen Commons Hub (siehe auch).
- Schnittstelle (2b):
- Hinzufügen und Entfernen von Mitteln
- Verändern von Mitteln (evtl. teilweise auch in (2a))
- Ob die Commons API hierfür verwendet werden kann, muss geprüft werden.
- Im einfachsten Fall kann das der Zugriff auf eine eigene Commons Booking Instanz sein, die alle Mittel verwaltet, die nicht von externen Plattformen kommen.
- Schnittstelle (2c):
- Anfrage von (privaten) Mitteln eines Benutzers
- Privatsphären-relevant
Komponente (3): Tätigkeitsmusterdatenbank
- Legt Tätigkeitsmuster strukturiert ab.
- Ein Tätigkeitsmuster umfasst mindestens:
- Beschreibung des Ablaufs der Tätigkeit
- Das Resultat der Tätigkeit in Form eines Mittelmusters (Verwendung der Schnittstelle (4a))
- Die Bedarfe der Tätigkeit in Form von Mittelmustern (Verwendung der Schnittstelle (4a))
- Tätigkeitsmuster müssen versioniert werden, jede Version muss eindeutig zugreifbar sein.
- Beispiele für Tätigkeitsmuster finden sich auf wikihow.com. Auch Open Source Ecology kennt etwas in der Art.
- Falls es verwendbare externe Musterdatenbanken gibt, sollten diese eingebunden werden. Beispielsweise wikihow.com (Lizenz, API).
- Komponente
patternsdes Mini-Prototypen - evtl. Realisierung auf Basis von MediaWiki möglich
- Schnittstelle (3a):
- Anfrage von Tätigkeitsmustern auf Grundlage des Mittelmusters von Resultaten
- Auslieferung nach dem Commons-API-Schema an (2) Mitteldatenbank (Commons Hub)
- Schnittstelle (3b):
- Anfrage von Tätigkeitsmustern mit Bedürfnisbefriedigung als Resultat
- Schnittstelle (3c):
- Hinzufügen und Verändern von Mustern
Komponente (4): Mittelmusterdatenbank
- Zentrale Komponente, die mit den Komponenten (1), (2) und (3) zusammenarbeitet.
- Stellt für jedes Mittel ein Mittelmuster bereit.
- Stellt für Resultate und Bedarfe von Tätigkeitsmustern Mittelmuster bereit.
- Ordnet jedem Mittelmuster einen Begriff der Wissensdatenbank zu (Verwendung der Schnittstellen (1a) und (1b))
- Schnittstelle (4a):
- Anfrage von Mittelmustern, bei Bedarf wird ein passendes Muster erstellt
Komponente (5): Matching und Konfigurationen
- Ermöglicht die Zusammenstellung von Tätigkeitsmustern und Mitteln zu Konfigurationen.
- Schnittstelle (5a):
- Anfrage von Konfigurationen für ein Tätigkeitsmuster nach bestimmten Kriterien
- Dazu Verwendung der Schnittstellen (1a), (2a), (3a) und (4a)
Komponente (6): Bedürfnisdatenbank
- Ablage von Bedürfnissen der Benutzer.
- Komponente
needsdes Mini-Prototypen - Schnittstelle (6a):
- Erstellen von Bedürfnissen
- Schließen von Bedürfnissen
- Abfrage von Bedürfnissen eines Benutzers
- Privatsphären-relevant
- Schnittstelle (6b):
- Abfrage aller Bedürfnisse
Komponente (7): Benutzerdatenbank
- Typische Benutzerdatenbank mit Registrierung.
- Legt Reputationskonten ab.
- Komponente
accountsdes Mini-Prototypen - Schnittstelle (7a):
- Anlegen und Löschen eines Benutzers
- Abfrage der Eigenschaften eines Benutzers
- Privatsphären-relevant
Komponente (8): Standard-Benutzerschnittstelle
- Vermutlich im Wesentlichen für mobile Endgeräte (App)
- Einfache Benutzerverwaltung (Schnittstelle (7a))
- Verwaltung der eigenen Bedürfnisse (Schnittstelle (6a))
- Verwaltung der von Mitteln (Schnittstellen (2b) und (2c))
- Zuordnung zu Tätigkeiten
- Kommunikationsfunktionen
Komponente (9): Verwaltungsbenutzerschnittstelle
- Schnittstelle für fortgeschrittene Benutzer
- Evtl. eher als Desktop-Webanwendung
- Verwaltung von Tätigkeitsmustern (Schnittstelle (3c))
- Verwaltung aller anderen Komponenten (insbesondere auch (1)), sofern nicht über Komponente (8) abgedeckt
- Evtl. könnte jede Komponente eine Art Plugin definieren, mit welchem sie Verwaltungsfunktionen für diese Oberfläche anbietet.
- Könnten zunächst die einfachen Views und das Admin-Interface des Mini-Prototypen sein.
Fehlende Komponenten
Es fehlen noch eine oder mehrere Komponenten für folgende Funktionen:
- Zuordnung von Tätigkeitsmustern zu Bedürfnissen (Verwendung der Schnittstelle (3b))
- Freischaltung von Konfigurationen für Bedürfnisse (Verwendung der Schnittstelle (5a))
- Zuordnung von Benutzern zu den Tätigkeiten einer freigeschalteten Konfiguration
- Aktivierung von Konfigurationen
- Abschließen eines Bedürfnisbefriedungsprozesses (siehe auch (6a))
- Kommunikationsfunktionen
 Ja genau, ich denke, das meine ich auch, nur dass ich mich damit nicht so gut auskenne. Die Komponente (1) ist so gemeint, dass sie alle (oder vermutlich eher einige) dieser Datenquellen unter einer für unsere Anwendung passenden Schnittstelle verfügbar macht. Wenn dein
Ja genau, ich denke, das meine ich auch, nur dass ich mich damit nicht so gut auskenne. Die Komponente (1) ist so gemeint, dass sie alle (oder vermutlich eher einige) dieser Datenquellen unter einer für unsere Anwendung passenden Schnittstelle verfügbar macht. Wenn dein